Parallel Processing in Python¶
author: Jacob Schreiber
contact: jmschr@cs.washington.edu
Simply put, parallel processing is splitting up a task between many CPUs to make it work faster or more efficiently. In the big data setting this often means speading up complex analyses by splitting up the task across the CPUs and getting a speedup bounded by the additional number of cores added. This is made easier because most tasks on big data are embarassingly parallel, which means having many independent tasks that can be distributed to many cores easily. For example, matrix-matrix multiplication can be time intensive for big matrices. However, each row-column dot product is independent from each other and so can be given to a core without the need to communicate between cores mid-task. This is great for parallel processing.
While languages like C, Java, and R allow parallel processing fairly easily, life isn't easy being a Python programmer due to the Global Interpreter Lock (or GIL). This is a lock on a Python process which prevents it from executing multiple threads simultaneously.
What does that even mean, though?
A process in a computer can be depicted as the following:
 (ref: https://web.kudpc.kyoto-u.ac.jp/manual/en/parallel)
(ref: https://web.kudpc.kyoto-u.ac.jp/manual/en/parallel)
Your computer will allocate some memory for each process, which can be thought of as basically a "program." Every program is isolated from the others, and no process is allowed to infringe on the memory space of another process. If a process attempts to infringe on a neighbors space, this can lead to everyone's favorite error, the segfault.
Inside a process there can be multiple "threads" of execution. These threads share the underlying memory of the process, and can each be assigned to different cores for execution. This makes parallelization nice, because a process can load up some data and then process it using multiple cores much many people might eat a birthday cake.
However, having shared memory can cause problems. For example, imagine trying to sum a trillion numbers and saving it to a local variable "x". At some point, one of your lines of code will look something like x = x + item. However, if multiple threads grab the old value of "x" at the same time, add some number to it, and try to update the variable, you will get mistakes called "race conditions" which will cause you to get an incorrect sum. What's even worse is that the simpler the task, the higher the probability of these happening due to the frequency that these variables are being called. Lets take a look at a simple code example (without focusing too much on what the code itself says.)
%load_ext Cython
%pylab inline
import seaborn, time
seaborn.set_style('whitegrid')
%%cython --compile-args=-fopenmp --link-args=-fopenmp --force
import numpy
cimport numpy
from cython.parallel import prange
cdef int x, i
with nogil:
x = 0
for i in prange(10000000, schedule='guided', num_threads=4):
(&x)[0] = (&x)[0] + 1
print x
Looks like we're getting a very wrong answer, and a different answer every time the code is run. This is where locks come in! Locks can be acquired by any thread and prevent other threads from executing. In this case, a thread could acquire a lock on x, update it, and then release the lock. This means only one thread is operating on x at a time. We can simulate that with the following code:
%%cython --compile-args=-fopenmp --link-args=-fopenmp --force
import numpy
cimport numpy
from cython.parallel import prange
cdef int x, i
with nogil:
x = 0
for i in prange(10000000, schedule='guided', num_threads=4):
with gil:
(&x)[0] = (&x)[0] + 1
print x
However, there can still be race conditions if multiple threads can read a variable but then acquire the gil to update it sequentially. In fact, we have exactly the same problem as before, where multiple threads can read a variable and then overwrite each other's progress. We're just doing it in a more orderly fashion instead of a chaotic fashion. See the following code:
%%cython --compile-args=-fopenmp --link-args=-fopenmp --force
import numpy
cimport numpy
from cython.parallel import prange
cdef int x, i, y
with nogil:
x = 0
for i in prange(1000000, schedule='guided', num_threads=4):
y = x + 1
with gil:
(&x)[0] = y
print x
Using the lock seemed to solve all of our issues, so what was the problem? Well, if we only have one thread running at a time, then we're not going to get any speed gain! Despite having distributed work to each of the seperate threads, only one of them is running at a time because we're constantly putting a lock on the work the threads are doing. We can see below roughly what was happening, where only one thread was allowed to do work at a time because it was acquiring and releasing a lock.

Now, the GIL is like a lock on a variable, except it's a lock on the entire Python process. This allows only one thread to be running at a time, no matter how many threads you create during the process of your program. This is a hotly contended issue amongst Pythonistas, but the general argument is that the Python interpreter was built to not be thread-safe because several speed gains could be made on that assumption, and since Python is pretty slow natively these speed gains are important.
It is still possible to do parallel processing in Python. The most naive way is to manually partition your data into independent chunks, and then run your Python program on each chunk. A computer can run multiple python processes at a time, just in their own unqiue memory space and with only one thread per process. This will be tedious, and you'll have to use another script to aggregate your answers. Pretty much, this sounds awful and you shouldn't do it.
This process can be automated using the multiprocessing module.
Multiprocessing¶
The simplest way to include parallel processing in your code is through the multiprocessing module which is built into python. The way this works is through the built-in pickle module, which is a way of serializing data, functions, and objects. In essense, you start up a pool of processes which wait for instructions from the main process. The main process will then send serialized data, methods, and objects, to the new process, and the new process will perform the instructions and send the result back.
The module has a relatively simple interface, where you write a python method, create a pool of workers, and execute that function for different inputs. Lets see it in action for the simple task of taking in a series of numbers and returning the number of items and their sum.
First, define the method:
def summarize( X ):
"""Summarize the data set by returning the length and the sum."""
return len(X), sum(X)
Now lets run this on a large amount of data in a purely sequential way to see what the answer is.
X = numpy.random.randn(1e7) + 8.342
x0, x1 = summarize(X)
print x1 / x0
Looks like we're recovering the mean fairly well, as would be expected given the large number of samples. Now lets time this:
%timeit summarize(X)
Seems fairly fast given that we have 1e7 elements. But it is a simple operation!
Using multiprocessing in Python involves first setting up a pool of workers and then distributing the tasks to each worker involving a subsection of the dataset.
from multiprocessing import Pool
p = Pool(4)
x = p.map( summarize, (X[i::4] for i in range(4)) )
print x
This returns a list with each element being the output of one of the jobs. We have to sum through each job now to get the total aggregate.
x0 = sum( y0 for y0, _ in x )
x1 = sum( y1 for _, y1 in x )
print x1 / x0
Looks like we're getting the same answer here! Now to time it:
n = len(X) / 4
%timeit p.map( summarize, (X[i*n:(i+1)*n] for i in range(4)) )
That looks like it's at least an order of magnitude slower! But we're using parallel processing, how could things ever be slower? The reason mostly revolves around the operation being too simple and the data being too small. Here are some of the more prominent reasons:
(1) The cost of setting up the worker pool is very high given the cost of the original operation:
%timeit -n 3 Pool(4)
(2) The memory cost of using this is high, because you're copying your initial data at least twice. This is because one full copy lives on the original process, and you have to send a partition of the data to this new process, which all has to live in memory.
(3) The cost of sending data across pipes can be higher than you want. Here is a speed comparison done by someone on StackOverflow:
mpenning@mpenning-T61:~$ python multi_pipe.py
Sending 10000 numbers to Pipe() took 0.0369849205017 seconds
Sending 100000 numbers to Pipe() took 0.328398942947 seconds
Sending 1000000 numbers to Pipe() took 3.17266988754 seconds
mpenning@mpenning-T61:~$ python multi_queue.py
Sending 10000 numbers to Queue() took 0.105256080627 seconds
Sending 100000 numbers to Queue() took 0.980564117432 seconds
Sending 1000000 numbers to Queue() took 10.1611330509 seconds
mpnening@mpenning-T61:~$ python multi_joinablequeue.py
Sending 10000 numbers to JoinableQueue() took 0.172781944275 seconds
Sending 100000 numbers to JoinableQueue() took 1.5714070797 seconds
Sending 1000000 numbers to JoinableQueue() took 15.8527247906 seconds
mpenning@mpenning-T61:~$(ref: http://stackoverflow.com/questions/8463008/python-multiprocessing-pipe-vs-queue)
This can be made faster, but it shows that especially for large datasets the time spent just piping the data can be significant.
So, if a significant portion of time is being spent piping data, then we can get better improvement with more cores if we have a more complex task. Basically each core is speeding through the summation and gulping down data as fast as possible. If we had a more complex task then the core would be spending more time on it and not need to be requesting new data as often.
Lets look at the case of pairwise sums, where we take in a list of numbers $x_{1}, \dots , x_{n}$ and return the sum of them all multiplied by each other, $\sum\limits_{i=1}^{n} \sum\limits_{j=1}^{n} x_{i}x_{j}$.
def scalar_sum(X, y):
return sum( x*y for x in X )
def pairwise_sum(X):
return( sum( scalar_sum(X, y) for y in X ) )
Now lets show the single process version time:
X = numpy.random.randn(1000)
%timeit pairwise_sum(X)
And a parallelized version. As a side note, we need a helper function to unwrap the arguments to the function since it has more than one function. It doesn't add a significant overhead to the program.
def scalar_wrapper(args):
return scalar_sum(*args)
p = Pool(4)
%timeit p.map( scalar_wrapper, ((X, y) for y in X) )
Looks like we're already getting a ~3x speed up when using 4 processes on this more complex operation!
Now, lets go to a real world example which can be very sped up using parallelization: Doing Expectation-Maximization on a Gaussian Mixture Model.
To begin with, a multivariate gaussian $G$ of dimensionality $d$ is parameterized by $mu$, which is a vector of mean values for each dimension, and $\Sigma$ which is the covariance matrix between all of these dimensions. The covariance matrix has a diagonal which is the variance of every dimension by itself, and each entry $\Sigma_{i,j}$ represents the covariance between dimension $i$ and dimension $j$.
A mixture model requires that its underlying components have two operations: (1) they can return probabilities of data given that component $P(D|M)$, and (2) they can be fit to data. The expectation-maximization procedure then iterates between these two operations, using Bayes rule to calculate the probability of each component producing each point, and then updating the components based on these weighted beliefs.
Multivariate Gaussians have both of these operations. (1) The probability of a point under the multivariate Gaussian is as follows:
\begin{equation} P(x|\mu, \Sigma) = \frac{1}{\sqrt{(2\pi)^{d}|\Sigma|}}exp\left(-\frac{1}{2}(x-\mu)^{T}\Sigma^{-1}(x-\mu)\right) \end{equation}Fortunately it's also implemented in scipy as a simple function for us. We can use this to create the expectation part of EM, which is calculating $P(M|D)$ for every data point and every component. We then normalize this matrix so that each row sums to 1, which defines the probability that each component generated that sample. Lastly, we do weighted MLE estimates to update the distributions.
We can see an example of it at work here:
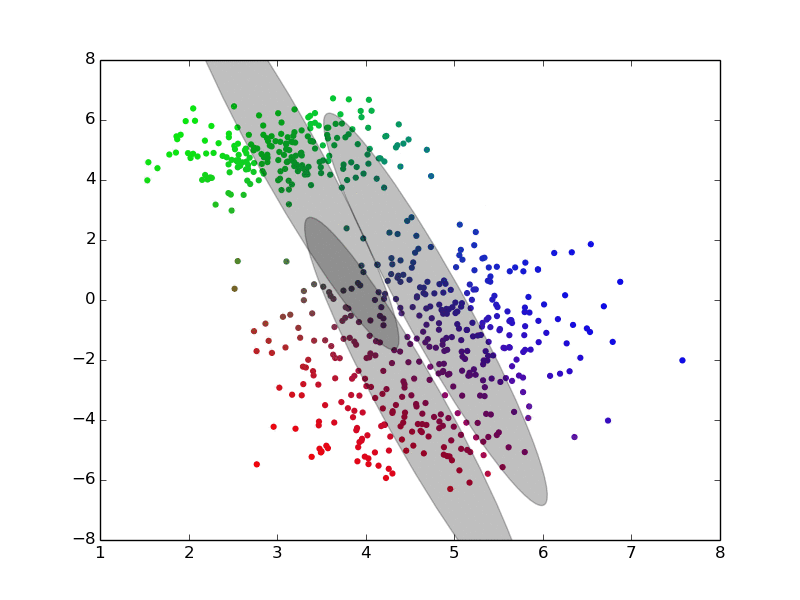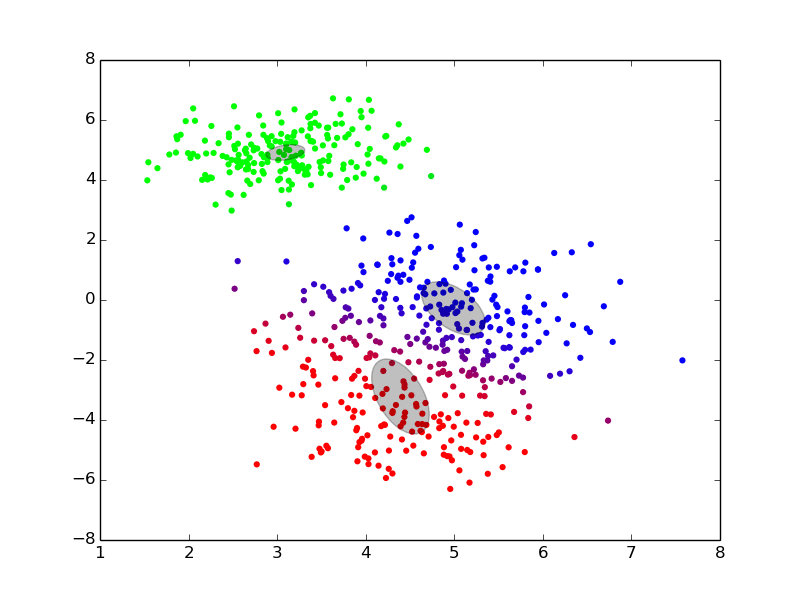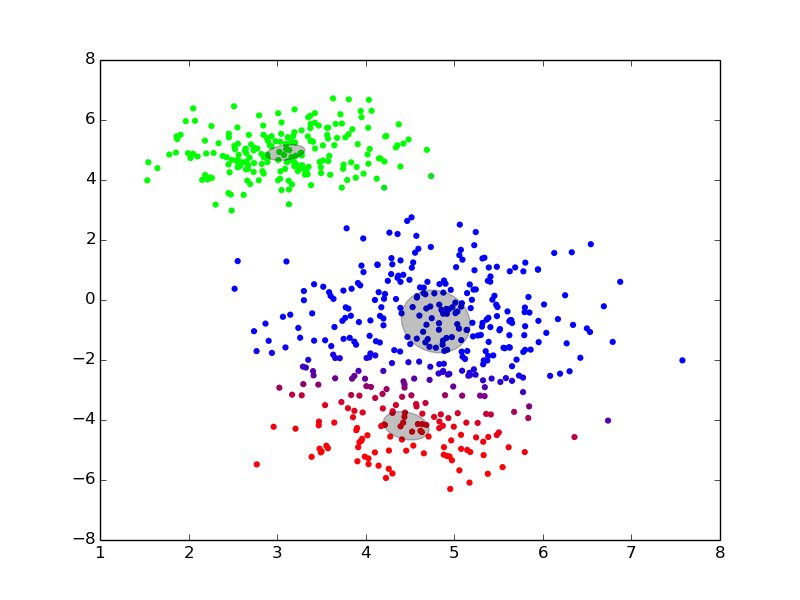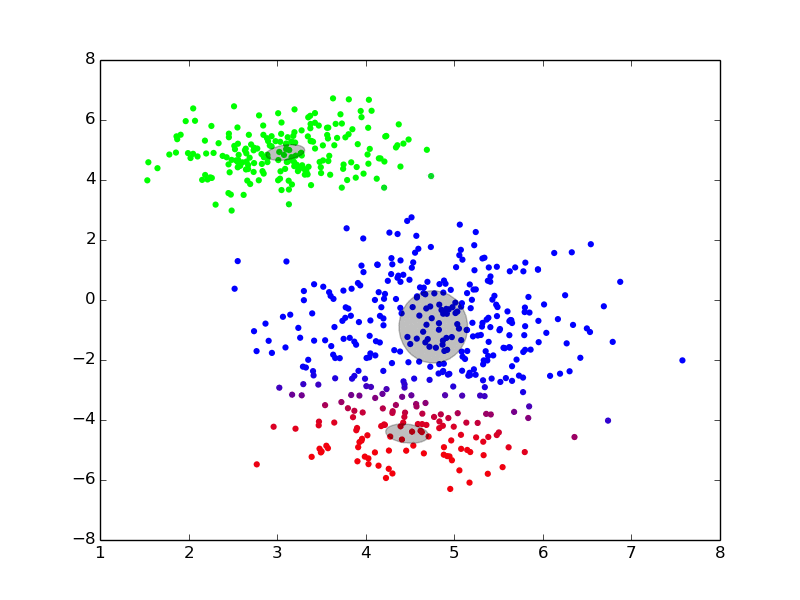 (ref: http://twitwi.github.io/Presentation-2015-dirichlet-processes/gmm2d/difficult-soft.gif)
(ref: http://twitwi.github.io/Presentation-2015-dirichlet-processes/gmm2d/difficult-soft.gif)
The colors added to the set are a bit confusing, but we can pretend that they don't matter. Roughly, we believe that the data was generated from three components, and want to be able to identify the underlying distributions which generated the data. We start off with rough, and very incorrect estimates, and then move towards better estimates iteratively until we converge at good solutions.
from scipy.stats import multivariate_normal
def expectation(X, mus, covs):
r = numpy.hstack([multivariate_normal.pdf(X, mu, cov)[:, numpy.newaxis] for mu, cov in zip(mus, covs)])
r = ( r.T / r.T.sum(axis=0) ).T
return r
def covariance(X, weights):
n, d = X.shape
mu = numpy.average(X, axis=0, weights=weights)
cov = numpy.zeros((d, d))
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
def maximization(X, r):
mus = numpy.array([ numpy.average(X, axis=0, weights=r[:,i]) for i in range(r.shape[1]) ])
covs = numpy.array([ covariance(X, r[:,i]) for i in range(r.shape[1]) ])
return mus, covs
We now have the two components which we need for the EM algorithm-- the expectation step and the maximization step. We just need to repeat these two steps until we achieve convergence. Instead of writing a convergence calculator we're just going to run the algorithm some fixed number of times until convergence,
def EM(X, mu, cov):
for i in range(50):
r = expectation(X, mu, cov)
mu, cov = maximization(X, r)
return mu, cov, r
Great. So we have a function now which will take in some initial values, and iterate until convergence, and return those values.
Lets generate some data with 4 underlying components
d, m = 2, 4
X = numpy.concatenate([numpy.random.randn(100000, d)+i*4 for i in range(m)])
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c='c', linewidth=0 )

Now lets run the sequential algorithm and plot the results.
initial_mu = numpy.random.randn(m, d) + X.mean(axis=0)
initial_cov = numpy.array([numpy.eye(d) for i in range(m)])
mu, cov = initial_mu.copy(), initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)

However, the calculation of the responsibility matrix in the expectation step is embarassingly parallel. We can either use model parallelism, where we break the model up across processes and have it analyze the same data, or data parallelism, where we break up the data across processes and have the full model analyze the partition of the data.
If we try to do this using the multiprocessing module, we will usually run into a memory error. This is because we have to create a new pool of workers each process, and pipe the data to each worker. The module doesn't have great shutting down of idle processes, and so in an iterative algorithm like EM you will frequently get several hundreds of idle processes all with a huge slice of the data taking up memory. Since we are implementing model parallelism, this gets especially bad, because each process will have a full copy of the data stored on it.
How do we deal with this, then?
joblib¶
joblib is a parallel processing library for python which was developed by many of the same people who work on scikit-learn, and is widely used inside scikit-learn to parallelize some of their algorithms. It is built on top of the multiprocessing and multithreading libraries in order to support both (multithreaded will be talked about later) but has a significant portion of additional features. One of the biggest ones is the ability to use a pool of workers like a context manager which can be reused across many tasks to be parallelized. This means each iteration of EM can use the same pool of workers. Newer versions will also actively time the duration of the tasks being dispatched to the processes to create an optimal schedule for splitting up data chunks. Lastly, if the number of jobs is set to 1, it will work in a purely sequential mode, with no overhead of setting up a pool or dispatching data.
Lets see how to use it below:
from joblib import Parallel, delayed
def _expectation(X, mu, cov):
return multivariate_normal.pdf(X, mu, cov)[:, numpy.newaxis]
def _expectation_wrapper(args):
return _expectation(*args)
def expectation(X, mus, covs, parallel):
tasks = ((X, mu, cov) for mu, cov in zip(mus, covs))
r = numpy.hstack( parallel( delayed(_expectation_wrapper)(t) for t in tasks ) )
r = ( r.T / r.T.sum(axis=0) ).T
return r
def EM(X, mu, cov):
with Parallel(n_jobs=4) as parallel:
for i in range(50):
r = expectation(X, mu, cov, parallel)
mu, cov = maximization(X, r)
return mu, cov, r
mu, cov = initial_mu.copy(), initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)
It looks like we're not getting a speed increase despite using parallel processing. This is likely because of the overhead costs of setting up the pool and piping data between the processes can be quite high. It might be time to move back to multi-threading, since we're having limited success with multiprocessing.
Multithreading¶
We did not immediately use threading because the GIL prevented multiple threads from being executed at the same time. However, it is possible to release the GIL if we use cython, which is a compiler for both native Python code and its extension, also called Cython. Lets look into parallelizing the pairwise sum problem first in cython.
X = numpy.random.randn(5000)
Lets first take a look at the raw python code and see how long it takes.
def scalar_sum(X, y):
return sum( x*y for x in X )
def pairwise_sum(X):
return( sum( scalar_sum(X, y) for y in X ) )
%timeit pairwise_sum(X)
Now lets keep the code the same but turn cython on and see how long it takes.
%%cython
def scalar_sum(X, y):
return sum( x*y for x in X )
def pairwise_sum(X):
return( sum( scalar_sum(X, y) for y in X ) )
%timeit pairwise_sum(X)
Looks like we're getting a pretty good speed increase without even modifying the code!
Now lets use some static typing of variables to utilize the Cython extension language. Since scalar_sum is the primary workhorse, lets focus on just improving that one for now.
%%cython
cdef double scalar_sum(double[:] X, double y):
cdef int i
cdef double _sum = 0.0
for i in range(X.shape[0]):
_sum += X[i] * y
return _sum
def pairwise_sum(X):
return( sum( scalar_sum(X, y) for y in X ) )
%timeit pairwise_sum(X)
Looks like a pretty good speed increase there! Static typing is one of the main boosts in speed you can get from Cython, because it can be very expensive to have to infer the type for numerics if you have to constantly repeat the checks.
Now lets cythonize the pairwise_sum component as well, to make the entire thing written in the Cython extension language.
%%cython
cdef double scalar_sum(double[:] X, double y):
cdef int i
cdef double _sum = 0.0
for i in range(X.shape[0]):
_sum += X[i] * y
return _sum
cpdef pairwise_sum(double[:] X):
cdef int i
cdef double _sum = 0.0
for i in range(X.shape[0]):
_sum += scalar_sum(X, X[i])
return _sum
%timeit pairwise_sum(X)
Now lets remove the GIL. In order to remove the GIL we need to make sure that the code with the GIL removed obeys several rules:
(1) Only statically typed variasbles of C primitives (int, long, double...)
(2) Arrays must be represented using pointers instead of numpy arrays or memoryviews
(3) No python object or methods at all
(4) All functions called must be tagged with nogil at the end
We then specify when we want to remove the GIL through the use of a context manager with gil and with nogil depending on what you want to do.
Passing arrays of data to the C level form the Python level seems like it might be a daunting task at first. However, numpy has solved this problem relatively elegantly. You can simply use the following to extract a pointer from any numpy array:
cdef dtype* X_ptr = <dtype*> X_ndarray.dataThe .data attribute extracts the pointer to the underlying data, and dtype is whatever datatype is being stored. For example, most numerics are stored as a doubles, so we can do the following:
cdef double* X_ptr = <double*> X_ndarray.dataOne last consideration is that X_ndarray must be cast as a numpy array. If we haven't explicitly cast it we must explicitly cast it now:
cdef double* X_ptr = <double*> (<numpy.ndarray> X_ndarray).data%%cython
cimport numpy
cdef double scalar_sum(double* X, double y, int n) nogil:
cdef int i
cdef double _sum = 0.0
for i in range(n):
_sum += X[i] * y
return _sum
cpdef pairwise_sum(numpy.ndarray X_ndarray):
cdef int i, n = X_ndarray.shape[0]
cdef double* X = <double*> X_ndarray.data
cdef double _sum = 0.0
with nogil:
for i in range(n):
_sum += scalar_sum(X, X[i], n)
return _sum
%timeit pairwise_sum(X)
Now we can parallelize this function by changing the range to prange. There are a variety of great scheduling techniques to assign chunks of data to the various threads, but guided usually works the fastest in my experience.
%%cython --compile-args=-fopenmp --link-args=-fopenmp --force
cimport numpy
from cython.parallel cimport prange
cdef double scalar_sum(double* X, double y, int n) nogil:
cdef int i
cdef double _sum = 0.0
for i in range(n):
_sum += X[i] * y
return _sum
cpdef pairwise_sum(numpy.ndarray X_ndarray):
cdef int i, n = X_ndarray.shape[0]
cdef double* X = <double*> X_ndarray.data
cdef double _sum = 0.0
with nogil:
for i in prange(n, schedule='guided', num_threads=4):
_sum += scalar_sum(X, X[i], n)
return _sum
%timeit pairwise_sum(X)
However, a major problem is that we can't use openmp on Windows machines, so if you want to write code which works cross-platform, or just on Windows, you need to use a different solution. This is where joblib comes in again, because it has both a multiprocessing and a multithreading backend.
We can use the same scalar_sum code from before exactly, but we need to make a few modifications since joblib works on the python level, but releasing the gil requires you to be on the C level.
%%cython
cimport numpy
from joblib import Parallel, delayed
cdef double scalar_sum(double* X, double y, int n) nogil:
cdef int i
cdef double _sum = 0.0
for i in range(n):
_sum += X[i] * y
return _sum
cpdef double scalar_wrapper(numpy.ndarray X_ndarray, double y):
cdef double* X = <double*> X_ndarray.data
cdef double _sum
with nogil:
_sum = scalar_sum(X, y, X_ndarray.shape[0])
return _sum
cpdef pairwise_sum(numpy.ndarray X):
cdef double _sum
with Parallel(n_jobs=4, backend='threading') as parallel:
_sum = sum( parallel([delayed(scalar_wrapper, check_pickle=False)(X, y) for y in X ]) )
return _sum
%timeit pairwise_sum(X)
There is a lot of overhead here with going between python and cython as individual points are passed. So lets chunk the data and send all of the elements of $X$ which it is responsible for summing.
%%cython
cimport numpy
from joblib import Parallel, delayed
cdef double scalar_sum(double* X, double* y, int n, int m) nogil:
cdef int i, j
cdef double _sum = 0.0
for i in range(n):
for j in range(m):
_sum += X[i] * y[j]
return _sum
cpdef double scalar_wrapper(numpy.ndarray X_ndarray, numpy.ndarray y_ndarray):
cdef double* X = <double*> X_ndarray.data
cdef double* y = <double*> y_ndarray.data
cdef int n = X_ndarray.shape[0], m = y_ndarray.shape[0]
cdef double _sum
with nogil:
_sum = scalar_sum(X, y, n, m)
return _sum
cpdef pairwise_sum(numpy.ndarray X, int num_threads=1):
cdef double _sum
with Parallel(n_jobs=num_threads, backend='threading') as parallel:
_sum = sum( parallel([ delayed(scalar_wrapper, check_pickle=False)(X, X[i::num_threads]) for i in range(num_threads) ]) )
return _sum
X = numpy.random.randn(100000)
%timeit pairwise_sum(X, 1)
%timeit pairwise_sum(X, 4)
Looks like we're getting a near-linear speedup when we add more threads. Great!
Expectation-Maximization Revisited¶
Now lets go back to the expectation-maximization algorithm on Gaussian Mixture models. Previously we found that using joblib and multiprocessing to parallelize jobs did not help significantly, likely due to the high overhead of setting up multiple processes and then pipe data between them. Lets see if we can lower this overhead using threads instead of processes.
First, lets generate some data again, and create baseline parameter estimates to start at.
d, m = 2, 4
X = numpy.concatenate([numpy.random.randn(1000000, d)+i*5 for i in range(m)]).astype('float64')
initial_mu = numpy.random.randn(m, d)*4 + X.mean(axis=0)
initial_cov = numpy.array([numpy.eye(d) for i in range(m)])
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c='c', linewidth=0 )

Now, lets use the same code which we used before. We're going to need to get this code down to the cython level so that we can release the GIL and use multithreading. The most important function to ensure that the GIL is released for is the log probability function, because it takes up the most amount of time. This means that instead of using the convenient scipy function which we used before, we have to rewrite it ourselves. If the inner workings of log probability calculations don't interest you, ignore it! Otherwise, we basically need to pass in the inverse covariance matrix and the log of the determinant of the covariance matrix. Using these, we can easily calculate the log probability of each point under the given parameters.
First lets define the functions we won't change this entire time, the maximization step and the EM iterator.
def maximization(X, r):
mus = numpy.array([ numpy.average(X, axis=0, weights=r[:,i]) for i in range(r.shape[1]) ])
covs = numpy.array([ covariance(X, r[:,i], mus[i]) for i in range(r.shape[1]) ])
return mus, covs
def EM(X, mu, cov):
for i in range(25):
r = expectation(X, mu, cov)
mu, cov = maximization(X, r)
return mu, cov, r
Now lets define the expectation step functions which we will optimize, and the covariance calculator for the maximization step.
import numpy
LOG_2_PI = numpy.log(2*numpy.pi)
def log_probability(X, mu, inv_cov, log_det, d):
logp = 0.0
for i in range(d):
for j in range(d):
logp += (X[i] - mu[i]) * (X[j] - mu[j]) * inv_cov[i, j]
return -0.5 * (d * LOG_2_PI + log_det + logp)
def _expectation(X, mu, cov ):
n = X.shape[0]
d = X.shape[1]
log_det = numpy.linalg.slogdet(cov)[1]
inv_cov_ndarray = numpy.linalg.inv(cov)
r = numpy.zeros(n)
for i in range(n):
r[i] = numpy.exp(log_probability(X[i], mu, inv_cov_ndarray, log_det, d ))
return r
def expectation(X, mu, cov):
r = numpy.hstack((_expectation(X, m, c)[:, numpy.newaxis] for m, c in zip(mu, cov)))
r = ( r.T / r.T.sum(axis=0) ).T
return r
def covariance(X, weights, mu):
n, d = X.shape
cov = numpy.zeros((d, d))
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
mu = initial_mu.copy()
cov = initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)

Alright, looks like it's taking a fair amount of time to run this calculation on the data. Lets step through the steps we took to reduce this down to Cython that we did before. First, lets just turn on the Cython compiler and see what types of speed increases we can get from that.
%%cython
import numpy
LOG_2_PI = numpy.log(2*numpy.pi)
def log_probability(X, mu, inv_cov, log_det, d):
logp = 0.0
for i in range(d):
for j in range(d):
logp += (X[i] - mu[i]) * (X[j] - mu[j]) * inv_cov[i, j]
return -0.5 * (d * LOG_2_PI + log_det + logp)
def _expectation(X, mu, cov ):
n = X.shape[0]
d = X.shape[1]
log_det = numpy.linalg.slogdet(cov)[1]
inv_cov_ndarray = numpy.linalg.inv(cov)
r = numpy.zeros(n)
for i in range(n):
r[i] = numpy.exp(log_probability(X[i], mu, inv_cov_ndarray, log_det, d ))
return r
def expectation(X, mu, cov):
r = numpy.hstack((_expectation(X, m, c)[:, numpy.newaxis] for m, c in zip(mu, cov)))
r = ( r.T / r.T.sum(axis=0) ).T
return r
def covariance(X, weights, mu):
n, d = X.shape
cov = numpy.zeros((d, d))
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
mu = initial_mu.copy()
cov = initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)
Great! We didn't need to do anything differently but we still get a fairly nice speed gain. Almost all python scripts which have a lot of numeric calculations will experience a speed gain of, in my experience, around 30%.
The next step for cythonizing our code is to include static typing. This allows the cython compiler to turn for loops into C-for loops, which are significantly faster. As a note, despute xrange being faster and more memory efficient than range for large Python lists, use range when writing in cython. Lets also pull the pointer arrays out of the numpy arrays.
%%cython
import numpy
cimport numpy
LOG_2_PI = numpy.log(2*numpy.pi)
cdef double log_probability(double* X, double* mu, double* inv_cov, double log_det, int d):
cdef int i, j
cdef double logp = 0.0
for i in range(d):
for j in range(d):
logp += (X[i] - mu[i]) * (X[j] - mu[j]) * inv_cov[i + j*d]
return -0.5 * (d * LOG_2_PI + log_det + logp)
cpdef numpy.ndarray _expectation( numpy.ndarray X_ndarray, numpy.ndarray mu_ndarray, numpy.ndarray cov_ndarray ):
cdef int i, n = X_ndarray.shape[0], d = X_ndarray.shape[1]
cdef double log_det = numpy.linalg.slogdet(cov_ndarray)[1]
cdef numpy.ndarray inv_cov_ndarray = numpy.linalg.inv(cov_ndarray)
cdef numpy.ndarray r = numpy.zeros(n)
cdef double* inv_cov = <double*> inv_cov_ndarray.data
cdef double* mu = <double*> mu_ndarray.data
cdef double* X = <double*> X_ndarray.data
for i in range(n):
r[i] = numpy.exp(log_probability(X + i*d, mu, inv_cov, log_det, d ))
return r
def expectation(X, mu, cov):
r = numpy.hstack((_expectation(X, m, c)[:, numpy.newaxis] for m, c in zip(mu, cov)))
r = ( r.T / r.T.sum(axis=0) ).T
return r
cpdef numpy.ndarray covariance(numpy.ndarray X, numpy.ndarray weights, numpy.ndarray mu):
cdef int i, j, n = X.shape[0], d = X.shape[1]
cdef numpy.ndarray cov = numpy.zeros((d, d))
cdef double w_sum
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
mu = initial_mu.copy()
cov = initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)
That's a pretty nice speed gain! Now lets release the GIL for the important functions to get it ready for multithreading.
%%cython
import numpy
cimport numpy
from libc.math cimport exp as cexp
DEF LOG_2_PI = 0.79817986835
cdef double log_probability(double* X, double* mu, double* inv_cov, double log_det, int d) nogil:
cdef int i, j
cdef double logp = 0.0
for i in range(d):
for j in range(d):
logp += (X[i] - mu[i]) * (X[j] - mu[j]) * inv_cov[i + j*d]
return -0.5 * (d * LOG_2_PI + log_det + logp)
cpdef numpy.ndarray _expectation( numpy.ndarray X_ndarray, numpy.ndarray mu_ndarray, numpy.ndarray cov_ndarray ):
cdef int i, n = X_ndarray.shape[0], d = X_ndarray.shape[1]
cdef double log_det = numpy.linalg.slogdet(cov_ndarray)[1]
cdef numpy.ndarray inv_cov_ndarray = numpy.linalg.inv(cov_ndarray)
cdef numpy.ndarray r = numpy.zeros(n)
cdef double* inv_cov = <double*> inv_cov_ndarray.data
cdef double* mu = <double*> mu_ndarray.data
cdef double* X = <double*> X_ndarray.data
for i in range(n):
r[i] = cexp(log_probability(X + i*d, mu, inv_cov, log_det, d ))
return r
def expectation(X, mu, cov):
r = numpy.hstack((_expectation(X, m, c)[:, numpy.newaxis] for m, c in zip(mu, cov)))
r = ( r.T / r.T.sum(axis=0) ).T
return r
cpdef numpy.ndarray covariance(numpy.ndarray X, numpy.ndarray weights, numpy.ndarray mu):
cdef int i, j, n = X.shape[0], d = X.shape[1]
cdef numpy.ndarray cov = numpy.zeros((d, d))
cdef double w_sum
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
mu = initial_mu.copy()
cov = initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)
That is a pretty massive speed increase! Now lets try using multithreads with openmp and see what type of performance increase we can get.
%%cython --compile-args=-fopenmp --link-args=-fopenmp --force
from cython.parallel cimport prange
import numpy
cimport numpy
from libc.math cimport exp as cexp
DEF LOG_2_PI = 0.79817986835
cdef double log_probability(double* X, double* mu, double* inv_cov, double log_det, int d) nogil:
cdef int i, j
cdef double logp = 0.0
for i in range(d):
for j in range(d):
logp += (X[i] - mu[i]) * (X[j] - mu[j]) * inv_cov[i + j*d]
return -0.5 * (d * LOG_2_PI + log_det + logp)
cpdef numpy.ndarray _expectation( numpy.ndarray X_ndarray, numpy.ndarray mu_ndarray, numpy.ndarray cov_ndarray ):
cdef int i, n = X_ndarray.shape[0], d = X_ndarray.shape[1]
cdef double log_det = numpy.linalg.slogdet(cov_ndarray)[1]
cdef numpy.ndarray inv_cov_ndarray = numpy.linalg.inv(cov_ndarray)
cdef numpy.ndarray r_ndarray = numpy.zeros(n)
cdef double* inv_cov = <double*> inv_cov_ndarray.data
cdef double* mu = <double*> mu_ndarray.data
cdef double* X = <double*> X_ndarray.data
cdef double* r = <double*> r_ndarray.data
for i in prange(n, nogil=True, num_threads=4, schedule='guided'):
r[i] = cexp(log_probability(X + i*d, mu, inv_cov, log_det, d ))
return r_ndarray
def expectation(X, mu, cov):
r = numpy.hstack((_expectation(X, m, c)[:, numpy.newaxis] for m, c in zip(mu, cov)))
r = ( r.T / r.T.sum(axis=0) ).T
return r
cpdef numpy.ndarray covariance(numpy.ndarray X, numpy.ndarray weights, numpy.ndarray mu):
cdef int i, j, n = X.shape[0], d = X.shape[1]
cdef numpy.ndarray cov = numpy.zeros((d, d))
cdef double w_sum
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
mu = initial_mu.copy()
cov = initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)
It's almost two times faster! That's better, but we aren't seeing nearly the linear gain we would expect to see. This is because we implemented a data parallel algorithm, where the only thing parallelized is calculating the log probabilities. This is mostly because it's easier to implement. What if, instead, we implemented a model parallel scheme where each component is parallelized instead of the data?
%%cython --compile-args=-fopenmp --link-args=-fopenmp --force
from cython.parallel cimport prange
import numpy
cimport numpy
from libc.math cimport exp as cexp
DEF LOG_2_PI = 0.79817986835
cdef double log_probability(double* X, double* mu, double* inv_cov, double log_det, int d) nogil:
cdef int i, j
cdef double logp = 0.0
for i in range(d):
for j in range(d):
logp += (X[i] - mu[i]) * (X[j] - mu[j]) * inv_cov[i + j*d]
return -0.5 * (d * LOG_2_PI + log_det + logp)
cdef void _expectation( double* X, double* r, double* mu, double* inv_cov, double log_det, int n, int d ) nogil:
cdef int i
for i in range(n):
r[i] = cexp(log_probability(X + i*d, mu, inv_cov, log_det, d ))
cpdef expectation(numpy.ndarray X_ndarray, numpy.ndarray mu_ndarray, numpy.ndarray cov_ndarray):
cdef int i, n = X_ndarray.shape[0], d = X_ndarray.shape[1], m = mu_ndarray.shape[1]
cdef numpy.ndarray inv_cov_ndarrays = numpy.array([numpy.linalg.inv(c) for c in cov_ndarray])
cdef numpy.ndarray log_dets_ndarray = numpy.array([numpy.linalg.slogdet(c)[1] for c in cov_ndarray])
cdef numpy.ndarray r_ndarray = numpy.zeros((4, n), dtype='float64')
cdef double* inv_cov = <double*> inv_cov_ndarrays.data
cdef double* log_dets = <double*> log_dets_ndarray.data
cdef double* r = <double*> r_ndarray.data
cdef double* X = <double*> X_ndarray.data
cdef double* mu = <double*> mu_ndarray.data
for i in prange(4, num_threads=4, schedule='guided', nogil=True ):
_expectation(X, r + i*n, mu + i*d, inv_cov + i*d*d, log_dets[i], n, d)
r_ndarray = ( r_ndarray / r_ndarray.sum(axis=0) ).T
return r_ndarray
cpdef numpy.ndarray covariance(numpy.ndarray X, numpy.ndarray weights, numpy.ndarray mu):
cdef int i, j, n = X.shape[0], d = X.shape[1]
cdef numpy.ndarray cov = numpy.zeros((d, d))
cdef double w_sum
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
mu = initial_mu.copy()
cov = initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)
Looks like we're doing a bit better with a model parallel scheme than a data parallel scheme. This makes sense, because we can easily have each thread scan the dataset rather than constantly chopping up the dataset for the threads to see. Oftentimes data parallel schemes are easier to implement, whereas model parallel schemes can be more efficient.
Lastly, lets implement this with joblib. We're going to implement the model parallel version.
%%cython
import numpy
cimport numpy
from libc.math cimport exp as cexp
from joblib import Parallel, delayed
DEF LOG_2_PI = 0.79817986835
cdef double log_probability(double* X, double* mu, double* inv_cov, double log_det, int d) nogil:
cdef int i, j
cdef double logp = 0.0
for i in range(d):
for j in range(d):
logp += (X[i] - mu[i]) * (X[j] - mu[j]) * inv_cov[i + j*d]
return -0.5 * (d * LOG_2_PI + log_det + logp)
cpdef numpy.ndarray _expectation( numpy.ndarray X_ndarray, numpy.ndarray mu_ndarray, numpy.ndarray cov_ndarray ):
cdef int i, n = X_ndarray.shape[0], d = X_ndarray.shape[1]
cdef double log_det = numpy.linalg.slogdet(cov_ndarray)[1]
cdef numpy.ndarray inv_cov_ndarray = numpy.linalg.inv(cov_ndarray)
cdef numpy.ndarray r_ndarray = numpy.zeros(n)
cdef double* inv_cov = <double*> inv_cov_ndarray.data
cdef double* mu = <double*> mu_ndarray.data
cdef double* X = <double*> X_ndarray.data
cdef double* r = <double*> r_ndarray.data
with nogil:
for i in range(n):
r[i] = cexp(log_probability(X + i*d, mu, inv_cov, log_det, d ))
return r_ndarray
def expectation(X, mu, cov):
with Parallel(n_jobs=1, backend='threading') as parallel:
r = parallel([ delayed(_expectation, check_pickle=False)(X, m, c) for m, c in zip(mu, cov) ])
r = numpy.hstack([ a[:, numpy.newaxis] for a in r ])
r = ( r.T / r.T.sum(axis=0) ).T
return r
cpdef numpy.ndarray covariance(numpy.ndarray X, numpy.ndarray weights, numpy.ndarray mu):
cdef int i, j, n = X.shape[0], d = X.shape[1]
cdef numpy.ndarray cov = numpy.zeros((d, d))
cdef double w_sum
for i in range(d):
for j in range(i+1):
cov[i, j] = weights.dot( (X[:,i] - mu[i])*(X[:,j] - mu[j]) )
cov[j, i] = cov[i, j]
w_sum = weights.sum()
return cov / w_sum
mu = initial_mu.copy()
cov = initial_cov.copy()
tic = time.time()
mu, cov, r = EM(X, mu, cov)
toc = time.time() - tic
r = r.argmax(axis=1)
plt.figure( figsize=(14, 10) )
plt.scatter( X[:,0], X[:,1], c=['cmgr'[i] for i in r], linewidth=0 )
plt.show()
print "EM took {}s".format(toc)
While not as good as using prange and openmp, it still is a pretty nice speed increase. One of the reasons we aren't getting a linear speedup with this implementation is that we are still calculating both the covariance matrix, and the inverse of the convariance matrix, on the main thread. It is possible to parallelize these, but I didn't for the sake of simplicity here. The calculation of the covariance matrix especially can be fairly time intensive, if it means that only one thread can be running at a time.
I hope this was a useful introduction to the ways in which both multi-processing and multi-threading can be used in Python. I'd love to hear any comments or feedback you have on this tutorial.